Netzwerk-Dosen
Vorwort
Ich habe 2 Anläufe in großem zeitlichen Abstand (habe das Thema nach dem ersten Anlauf vermieden) gebraucht um das Thema wirklich zu verstehen. U.a. habe ich nicht verstanden wie man "gleichzeitig" senden und empfangen kann, ohne Daten zu verlieren oder wie man mehrere Verbindungen "gleichzeitig" verarbeiten kann.
Auch habe ich mehr als 1 Tutorial zur Hand nehmen müssen bevor ich zufrieden mit meinem Kenntnisstand war, ich hatte das Gefühl das bei allen immer verschiedene Teile fehlten.
Deswegen habe ich diesen Blog-Post verfasst um nach Möglichkeit das Thema so gut wie möglich zu erklären (für jemanden der ich sein könnte).
Voraussetzungen
-
Wissen was TCP und UDP ist
-
grundsätzlich Kenntnisse in Python
-
möglichst Linux um die Beispiele nachzuvollziehen
Um das eigene Server-Programm oder einen Client zu testen kann man netcat benutzen:
netcat 127.0.0.1 53444verbindet sich als Client mit dem Server der auf 127.0.0.1 und Port 53444 lauscht.
netcat -l 127.0.0.1 53444Arbeitet als "Server" (-l → listen).
Was immer man tippt nach dem die Verbindung aufgebaut ist wird an die Gegenstelle gesendet.
Was die Gegenstelle sendet wird ausgegeben.
Per Ctrl+C kann die Verbindung beendet werden.
Zum Verständnis vorweg
Man arbeitet mit sogenannten Sockets (also Steckdosen).
Ein Socket ist ähnlich wie bei Dateien das Filehandle letzten Endes eine Nummer die sich Programm und Betriebssystem teilen um zu wissen über welche Ressource sie reden.
Ein Socket repräsentiert dabei:
-
einen Port der auf eingehende Verbindungen lauscht (lokale Adresse + lokaler Port)
-
eine Verbindung zwischen dem lokalen System und einem Remote-System (lokale Adresse + lokaler Port und entfernte Adresse + entfernter Port)
Die Ebene auf der der Socket bei TCP/IP bzw. UDP arbeitet (gibt noch andere Sockets) ist oberhalb von TCP/UDP, also auf Schicht 5 von ISO/OSI.
Das heißt mit den Ebenen darunter hat man sehr indirekt zu tun und auch nur indirekt Einfluss (über Konfigurations-Parameter). Man hat also keinen direkten Einfluss bzw. muss sich nicht um Routing,
Paketierung, Auf- und Abbau (indirekt schon, aber nicht um die Handshakes), Buffering/Flow-Controll (bei UDP mehr, bei TCP nicht) usw. kümmern.
All diese Arbeiten übernimmt auch nicht Python, oder irgendeine Bibliothek in Python (jedenfalls nicht auf normalen Betriebssystemen, im Embedded-Bereich sieht es anders aus), sondern das Betriebssystem.
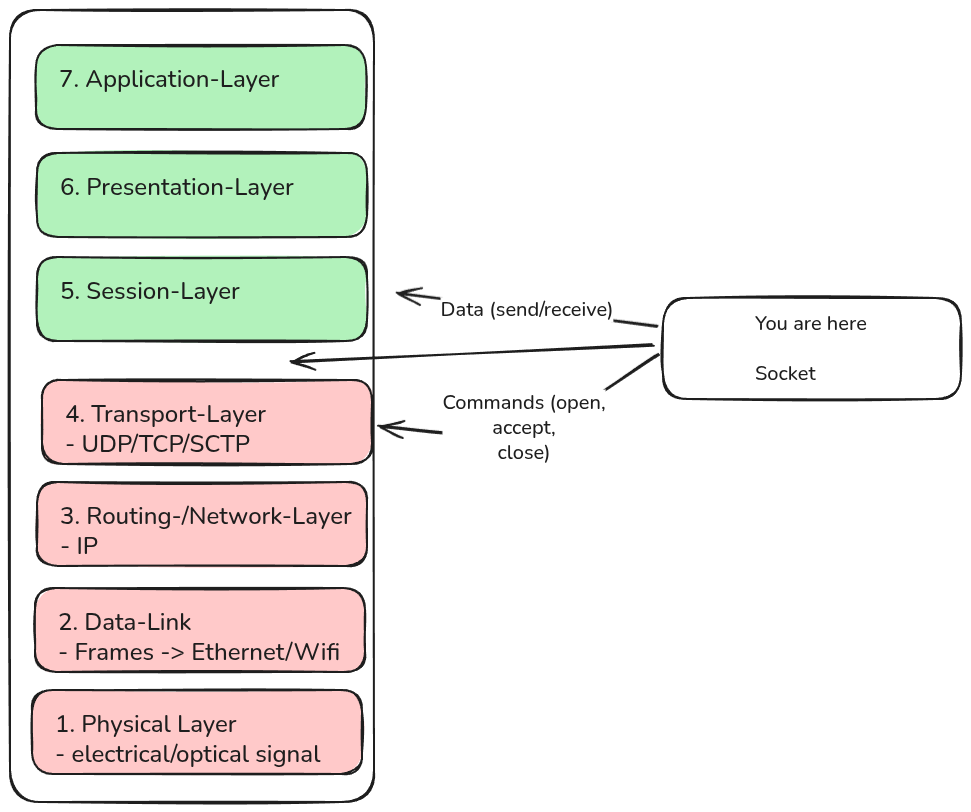
Der rote Bereich wird durch das Betriebssystem gehandhabt, der grüne Bereich ist unser Problem.
Genaugenommen geben wir an den roten Bereich über den Socket Befehle, in dem wir einen Socket erstellen, schließen und andere Befehle an ihn geben, aber die eigentlichen daraus resultierenden Arbeiten auf den rot markierten Schichten übernimmt das Betriebssystem für uns. Der grüne Bereich ist das was wir implementieren müssen.
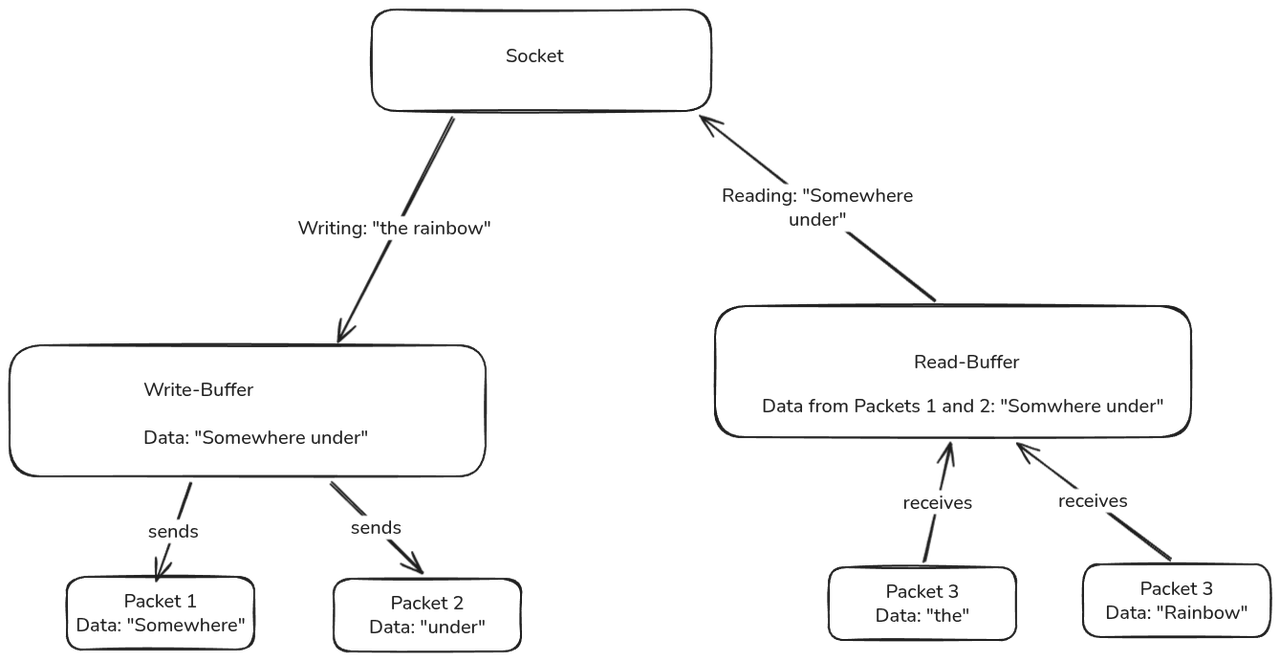
Die Daten die gelesen werden stammen direkt aus dem Daten-Teil der Pakete (TCP oder UDP), allerdings ließt man nicht die Daten aus einem Paket, sondern alle bisher eingegangenen Daten hintereinander weg.
Die Pakete landen auf Seiten des Betriebssystems in einem Puffer, und der Socket greift auf diesen zu.
Das gleiche passiert beim Schreiben, es werden keine einzelnen Pakete geschrieben, sondern in den Puffer für diese Verbindung, das Betriebssystem packt die Daten dann in Pakete.
Ein einfacher Server
-
Akzeptiert eine Verbindung gleichzeitig
-
ließt Daten
-
sendet die eingehenden Daten zurück + "blablabla"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import socket
HOST = "127.0.0.1"
PORT = 65445
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as listening_socket:
# Bind to the host and port
listening_socket.bind((HOST, PORT))
# Start listening for incomming connections -> port reachable by client
listening_socket.listen()
# Establish a connection when a connection came in -> connection to client established
conn_socket, addr = listening_socket.accept()
with conn_socket:
while True:
# Read data when available -> maximum 1024 bytes at once
data = conn_socket.recv(1024)
# If data is empty this means the connection has been terminated by the client
if not data:
break
# Send back to client whatever has been received + blablabla
conn_socket.sendall(data.strip() + b", blablabla\n")
1. Socket-Bibliothek wird importiert.
6. Erstellt einen neuen Socket, dabei muss die Familie (AF_INET für IP) und das Transport-Protokoll (SOCK_STREAM für TCP) angegeben werden.
Der with-Block stellt sicher das am Ende oder im Falle einer Exception listening_socket.close() aufgerufen wird und der Socket geschlossen wird. Das ist wichtig, da sonst bestehende Verbindungen nicht beendet werden und der Port blockiert (kein Programm kann den Port nutzen) bleibt bis diese ausgetimed sind. Kann man keinen with-Block nutzen, sollte man die Socket-Aktionen in einen try-except-Block einfassen und im except oder finally-Block die Verbindung schließen.
Der Socket der hier erstellt wird ist der listening-Socket, also der der auf eingehende Verbindungen warten wird.
8. Der Listening-Socket wird an einen Host und Port (in diesem Fall an localhost und Port 65445) gebunden. An der Stelle ist nur der Port und Adresse reserviert.
10. listen() sorgt dafür das der Port (geöffnet wird).
Das heißt wird ein syn-Paket (im Falle von TCP) an diesen Port gesendet wird keine ICMP gesendet was sagt das der Port geschlossen ist. Statt dessen wird die die Anfrage gespeichert, aber nicht beantwortet.
Die Menge der Verbindungs-Anfragen die gespeichert wird lässt sich als Parameter an listen() übergeben → listen(10) → 10-Verbindungsanfragen werden gepuffert
12. listening_socket.accept() akzeptiert eine Verbindung aus dem gepufferten Verbindungen.
Für diese Verbindung wird dann (im Falle von TCP) Syn/Ack gesendet.
listen() gibt einen Socket und Adress-Daten zurück. Der Socket repräsentiert die Verbindung und alle Aktionen für diese Verbindung finden über diesen Socket statt. Die Adress-Daten sind ein Tupple welches IP und Port der Gegenstelle darstellen.
13. Der With-Block dient wiederum nur dazu, dass sobald der Block verlassen wird oder eine Exception auftritt der Socket ordnungsegmäß geschlossen wird
16. conn_socket.recv(1024) ließt bis zu 1024 Byte Daten aus dem Puffer des Sockets.
Sind weniger Daten vorhanden werden weniger Daten zurückgegeben, sind mehr Daten vorhanden werden 1024 Byte Daten zurückgegeben.
Der Aufruf blockiert (die Ausführung wird gestoppt) bis Daten vorhanden sind oder die Verbindung beendet wurde.
Die Daten sind Binärdaten und müssen entsprechend dekodiert werden → data.decode("utf-8") → wenn sie UTF8-kodiert sind z.b.
18. Wenn keine conn_socket.recv() keine Daten (leerer String) zurückgegeben hat, dann bedeutet das, dass die Gegenseite die Verbindung abgebaut hat.+
Ein Aufrufen von conn_socket.close() ist weder möglich, noch nötig an dieser Stelle (auch wenn es nicht in einem with-Block wäre), da in dem Moment wo die Gegenseite die Verbindung abbaut, das Betriebssystem ohne das Warten auf close() die Verbindung komplett abbaut (also FIN, ACK sendet). Der Socket existiert nach dem letzten Aufruf von recv() nicht mehr.
close() (bzw. indirekt per with-Block) ist nur notwendig, wenn "wir" die Verbindung abbauen wollen und nicht der Client/Gegenstelle.
21. conn_socket.sendall(data) sendet die Daten in data. Die Daten müssen als Binärdaten vorliegen, das heißt sie müssen ggf. encoded werden → data.encode("utf-8").
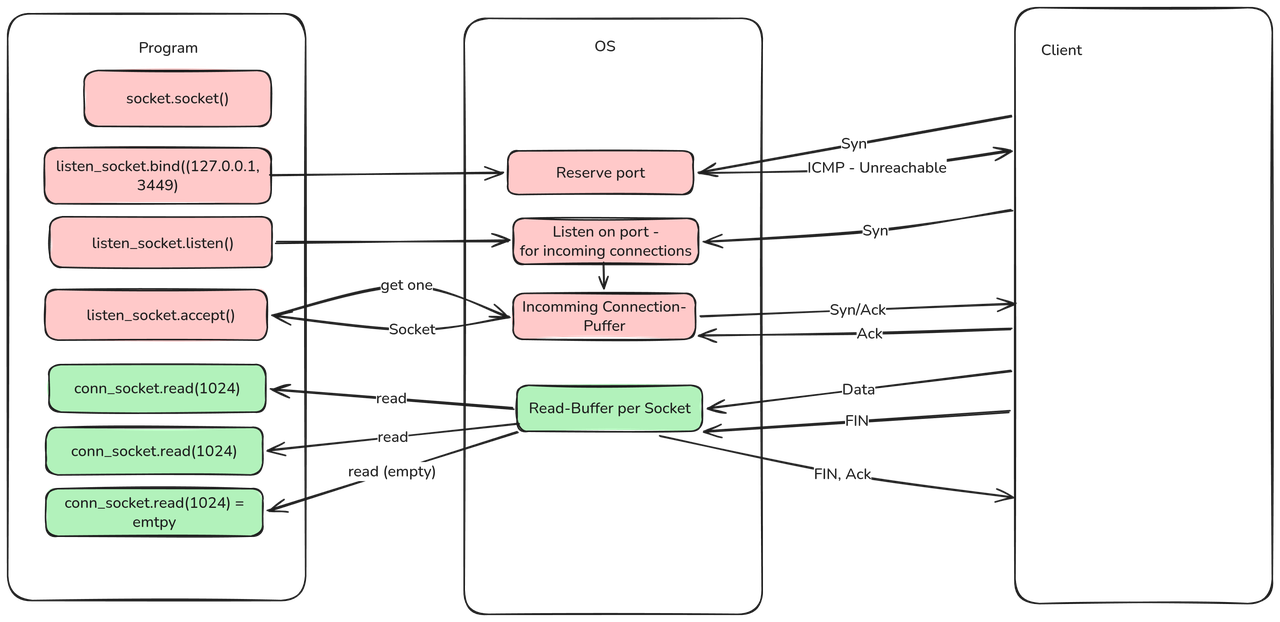
Die roten Blöcke betreffen den Listen-Socket, also den Socket der auf eingehende Verbindungen wartet.
Die grünen Blöcke sind die mit dem Connection- oder Verbindungs-Socket assoziiert, diese gibt es für jede Verbindung separat.
Ein einfacher Client
1
2
3
4
5
6
7
8
9
10
import socket
HOST = "127.0.0.1"
PORT = 65445
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as sock:
sock.connect((HOST, PORT))
sock.sendall(b"Hallo du Mensch")
data = sock.recv(1024)
print(data)
1. Import der Socket-Library
6. Erstellen eines Sockets.
Es wird wie beim Server die Protokollfamilie (AF_INET für IP) und das Transportprotokoll (SOCK_STREAM für TCP) angegeben.
Das ganze erfolgt in einem with-Block, so dass am Ende des Blocks oder beim Autfreten einer Exception der Socket geschlossen wird.
7. sock.connect() verbindet sich mit dem Server (erledigt den ganzen Aufbau, Syn, warten auf Syn-Ack und senden von Ack).
Es wird der Host und der Port zu dem sich verbunden werden soll als Tupple übergeben.
8. sock.sendall(String) sendet den angegebenen String an die Gegenstelle.
Der String muss ein Byte-String sein, eine normale Zeichenkette muss ggf. vorher encoded werden → data.encode("utf-8") → wobei data hier das zu kodierende String-Objekt wäre.
Wie auf Server-Seite schreibt man hier in einen Puffer im Betriebssystem und das kümmert sich um die Pakettierung und ggf. retransmissions usw.
9. sock.recv(1024) ließt Daten (bis zu 1024 Byte, weniger wenn weniger im Puffer sind) die der Server gesendet hat.
Wie auch beim Server wird aus einem Puffer gelesen, je nach dem wie viel Daten vorhanden sind kann auch weniger als das Maximum gelesen werden.
Wie auf Server-Seite auch blockiert recv() bis Daten vorhanden sind oder die Verbindung beendet wird durch die Gegenstelle (in dem Fall gibt recv einen leeren String zurück).
Die empfangenen Daten sind ein Byte-String, um einen "normalen" String daraus zu machen muss man sie ggf. decodieren → data.decode("utf-8").
Server mit mehreren Verbindungen (per loop)
Der Server in obigem Beispiel kann nur eine Verbindung (gleichzeitig) handhaben.
Das liegt daran das:
1data = conn_socket.recv(1024)
blockierend arbeitet, d.h. bis Daten empfangen werden auf diesem Socket, wird das Programm angehalten.
Die Lösung ist den Socket auf Non-Blocking zu setzen, das heißt Vorgänge wie accept() und recv() geben umgehend ein Ergebnis zurück, auch wenn in dem Moment keine eingehenden Verbindungen oder Daten im Lese-Puffer sind.
Ein Server könnte dann so aussehen:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
import socket
HOST = "127.0.0.1"
PORT = 65445
connections = []
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as listening_socket:
# Bind to the host and port
listening_socket.bind((HOST, PORT))
# Start listening for incomming connections -> port reachable by client
listening_socket.listen()
listening_socket.setblocking(False)
while True:
# Establish a connection when a connection came in -> connection to client established
try:
conn_socket, addr = listening_socket.accept()
except BlockingIOError:
pass
else:
conn_socket.setblocking(False)
print(f"New connection {addr[0]}:{addr[1]}")
connections.append(conn_socket)
for conn_socket in connections:
try:
# Read data when available -> maximum 1024 bytes at once
data = conn_socket.recv(1024)
# If data is empty this means the connection has been terminated by the client
if not data:
connections.remove(conn_socket)
# Send back to client whatever has been received + blablabla
conn_socket.sendall(data.strip() + b", blablabla\n")
except BlockingIOError:
pass
12. Setzt den listening_socket auf Nicht-blockierend → setblocking(False)
14. Leitet eine Schleife ein, die fortwährend prüft ob eingehende Verbindungen vorhanden sind oder Daten gelesen werden können aus einem bestehenden Socket
16. Da der listening_socket nicht mehr blockiert führt der Aufruf von accept() (Zeile 17) zu einem BlockingIOError wenn keine neuen Verbindungen im Verbindungs-Puffer sind. Das ist kein Fehler, muss nur abgefangen werden.
21. Wurde eine neue eingehende Verbindung gefunden (es gab keine Exception → try-else):
Wird der neue connection_socket der für diese Verbindung steht auch auf Non-Blocking gesetzt → conn_socket.setblocking(False)
Der Socket zur Liste von offenen Verbindungen hinzugefügt (Zeile 23)
25. Es wird über die offenen Verbindungen geloopt und geguckt ob irgendeiner der Sockets Daten zur Verfügung stellt
26. Die Abfrage ob Daten vorliegen (conn_socket.recv() - Zeile 28) resultiert im Falle das keine Daten vorhanden sind in einem BlockingIOError (wie bei accept()), daher der try-Except-Block.
31. Wurden keine Daten empfangen (und es gab keine Exception) dann wurde der Socket geschlossen.
Entsprechend wird der Socket aus der Liste der offenen Sockets entfernt.
Dieses Vorgehen hat aber einen Nachteil: Es benutzt eine Schleife die kontinuierlich alle Sockets abfragt. Das bedeutet das Programm lastet einen CPU-Kern permanent komplett aus, nur damit ständig Sockets abzufragen, egal ob es etwas zu tun gibt oder nicht!
Server mit selector
Um zu vermeiden, dass das Programm ständig die Sockets abfragen muss, obwohl nichts zu tun ist, bringen die meisten Betriebssysteme einen eingebauten Mechanismus mit.
Diese heißen poll, epoll oder select (daher selector).
Diese erlauben eine Liste von Sockets zu übergeben und Ereignissen (Mask) an denen man interessiert ist zu übergeben und stellen einen Aufruf zur Verfügung der die Liste von Sockets zurückliefert bei denen es seit dem letzten Abruf ein gewünschtes Ereignis gegeben hat.
Das heißt nicht mehr das Programm fragt ständig alle Sockets einzeln ab, sondern das Betriebssystem (was die Verbindungen sowieso verwaltet) gibt dem Programm eine Liste von Sockets wo Änderungen vorliegen.
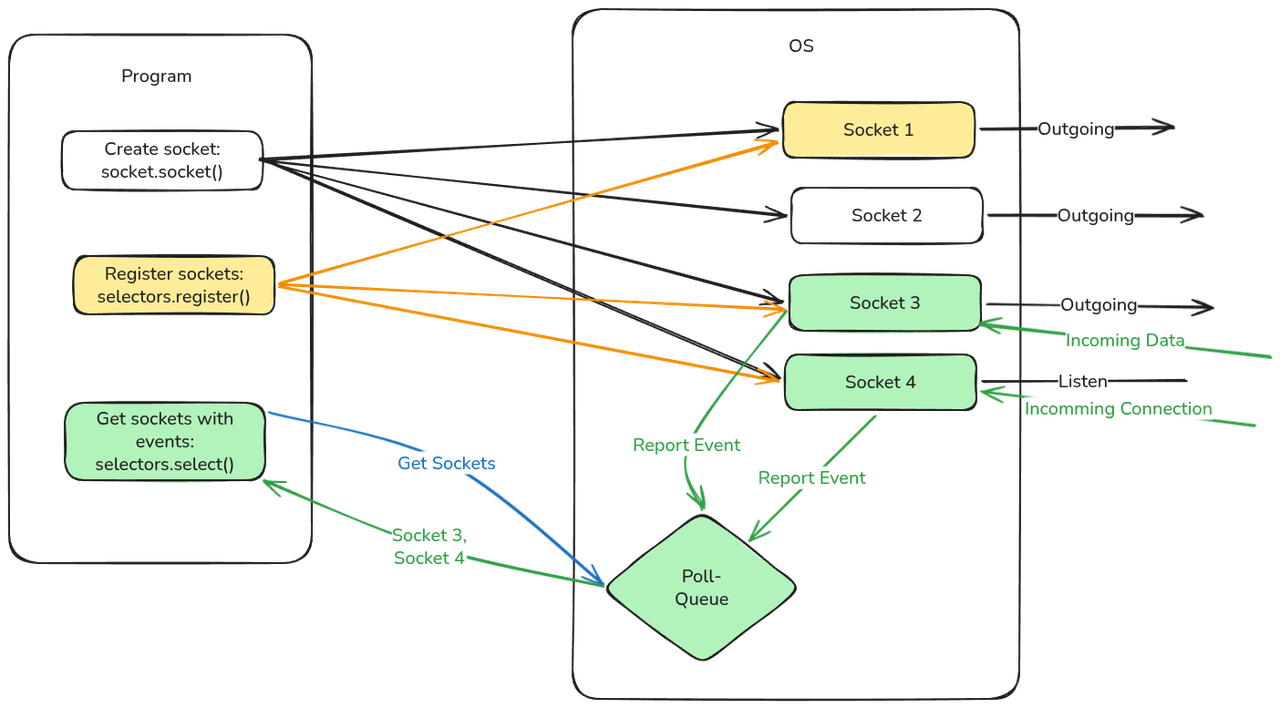
-
selectors.register() registriert bestehende Sockets mit einem selector
-
über eine Maske kann angeben werden bei welchen Ereignissen der Socket zurückgegeben werden soll
-
-
sobald auf einem der Sockets ein Ereignis eingeht das von der Maske erfasst ist → z.B. ein Read-Event durch eingehende Daten oder eine eingehende Verbindung auf einem Socket der auf solche wartet wird der Socket zu einer Queue (Liste) hinzugefügt
-
per selectors.select() wird die Liste der Sockets abgerufen bei der ein Event (durch die Maske abgedeckt) aufgetreten ist seit dem letzten Aufruf von select()
In obigem Bild wurden Socket1, Socket 3 und 4 mit einem selector registriert (Socket 2 nicht).
Für Socket 1 gibt es kein Event, für Socket 3 kommen Daten herein und Socket 4 wartet auf eingehende Verbindungen und eine Verbindung geht ein. Entsprechend landen Socket 3 und 4 in der Queue (1 nicht, da kein Event vorhanden und 2 nicht, weil nicht Teil des Selectors).
Beim Aufruf von socket.select() durch das Programm wird Socket 3 und 4 als die Sockets mit Events zurück gegeben und das Programm kann dann anschließend auf die Events reagieren.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
import socket
import selectors
HOST = "127.0.0.1"
PORT = 65445
selector = selectors.DefaultSelector()
def accept(sock, mask):
incomming_sock, addr = sock.accept()
print("Incomming connection", addr)
incomming_sock.setblocking(False)
selector.register(incomming_sock, selectors.EVENT_READ | selectors.EVENT_WRITE, process)
def process(sock:socket.socket, mask):
if mask & selectors.EVENT_WRITE:
print(mask)
pass
if mask & selectors.EVENT_READ:
print(mask)
try:
data = sock.recv(1024)
except BlockingIOError:
return
if data:
print("Data:", data)
sock.sendall(b"Zurueck" + data)
else:
print("Terminating connection")
selector.unregister(sock)
# sock.close()
# No with-block here, as it will close the socket after leaving the
# block (which it will)
listening_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
listening_socket.bind((HOST, PORT))
listening_socket.listen(5)
listening_socket.setblocking(False)
# If something is being read at the socket -> its a incomming connection
# The socket is the one listening -> waiting for incomming connections, so not a connection A<->B
# The last parameter will be accessible in the key-object in the event as key.data -> you can put
# whatever you like in it (any object), most times you at least want the call back function here
selector.register(listening_socket, selectors.EVENT_READ, data=accept)
while True:
# Get the list of "event" happened since last time select() has been run for the registered sockets
events = selector.select()
# Unpack the list
for key, mask in events:
callback_function = key.data
socket = key.fileobj
callback_function(socket, mask)
2. Importiert die selector-Bibliothek. Nicht zu verwechseln mit "select", was die Low-Level-Bibliothek ist
7. Instanziert einen DefaultSelector. Es gibt verschiedene Selector-Implementierung, je nach Betriebssystem stehen ggf. auch verschiedene zur Verfügung. DefaultSelector wählt automatisch eine passende. 9. - 32. kommt später hier im Text.
33. An dieser Stelle ist kein with-Block, auch wenn er Sinn hätte. Das Problem ist das ein Socket instanziert wird (der listening-Socket), aber dieser wird in Zeile 43 an die register()-Funktion übergeben und der Code danach weiter ausgeführt → der Block würde verlassen werden und damit der übergebene Socker geschlossen
35. - 37. Erstellt einen TCP-Socket und setzt ihn auf lauschend für eingehende Verbindungen → listen(5) → maximal 5 eingehende Verbindungen bis accept() aufgerufen werden muss oder keine neuen Verbindungen mehr auf "Halde" eingehen können.
38. Setzt den listening_socket auf Nicht-Blockierend.
43. Registriert den Socket (listening_socket) mit dem selector. Das bedeutet der Socket wird absofort durch das Betriebssystem überwacht und Ereignisse (events) dafür gesammelt.
Erster Parameter ist der Socket selbst.
Zweiter Parameter ist die Mask bzw. Maske die definiert welche Ereignisse (Events) von Interesse sind und nur diese werden zurückgeliefert. Es handelt sich um eine Bit-Maske, die möglichen Optionen sind über selectors.EVENT* → selectors.EVENT_READ, selectors.EVENT_WRITE usw. zugänglich. Mehrere Events können über den Bit-Oder-Operator "|" kombiniert werden → "selectors.EVENT_READ | selectors.EVENT_WRITE" würde sowohl auf Lese- als auch auf Schreib-Events warten. Eingehende Verbindungen auf einem "listening"-Socket sind über Lese-Ereignisse abgedeckt bzw. gelten als solche.
Dritter Parameter ist data. Data ist ein beliebiges benutzerspezifisches Objekt was mit dem Socket verknüpft werden soll. Das wird mit dem Event und Socket später zurück gegeben und kann genutzt werden um weitere Informationen zu speichern. Häufig wird es genutzt um eine Call-Back-Funktion (die Funktion die im Falle eines Events für diesen Socket aufgerufen werden soll) zu speichern - das ist sinnvoll da der gleiche selector ja sowohl die Verbindungs-Sockets (also wo Client und Server Daten austauschen) als auch den Listening-Socket (worüber neue Verbindungen eingehen) überwacht und man sonst nicht auseinanderhalten kann ob ein Read-Event Daten oder eine eingehende Verbindung sind (abhängig vom Socket), da es in beiden Fällen ein Read-Event und in beiden Fällen einfach ein Socket-Objekt ohne Unterscheidungsmöglichkeit ist (wird ggf. später etwas klarer)
45. Startet eine Schleife die den selector nach Events abfragt und dann ggf. die Liste der Events/Sockets mit Events abarbeitet
47. selector.select() ist ein blockierender Aufruf, d.h. das Programm stoppt hier bis mind. einer der Sockets die registriert sind ein Ereignis/Event aufweist. Optional kann ein Timeout an die Funktion übergeben werden.
Hatte mind. ein Socket seit dem letzten aufruf von select() ein Ereignis wird eine Liste von Events zurückgegeben.
49. Durchläuft die Liste von Events und entpackt sie.
Events bestehen aus einem key (der wiederum Attribute hat) und einer Mask/Maske. Die Maske ist eine Bit-Mask die mitteilt welches Event vorliegt (selectors.EVENT_READ oder selectors.EVENT_WRITE z.B.).
50. - 51. Zerlegt den key weiter.
key.data enthält das Objekt das wir bei selector.register() als letzten Parameter bzw. data-Parameter angegeben haben für diesen Socket. In obigem Beispiel ist das die Call-Back-Funktion. Für den listen_socket haben wir dort die accept-Funktion hinterlegt, im späteren Code werden wir für die connection-Sockets dort die Funktion process hinterlegen.
key.fileobj enthält den eigentlichen Socket (wie man sieht handelt es sich dabei im Prinzip um einen File-Descriptor)
52. Ruft die Funktion die mit dem Socket über das data-Attribut verknüpft ist auf und übergibt den Socket und die Maske
10. Ist die Funktion die aufgerufen wird wenn auf dem listening-Socket ein Ereignis auftritt.
11. Ruft accept() auf, um die eingehende Verbindung anzunehmen.
13. Setzt den neu enstandenen Verbindungs-Socket auf Non-Blocking
14. Registriert den neu entstandenen Verbindungs-Socket mit dem selector, so dass Events auf diesem später wieder über select() abrufbar sind.
Als Maske wird hier "selectors.EVENT_READ | selectors.EVENT_WRITE" angegeben, es soll also auf Lese- und Schreibereignisse gelauscht werden. Die Maske ist eine Bit-Maske, der "|"-Bit-Operator kombiniert beide Masken. Praktisch bräuchte man in der Regel nur auf EVENT_READ lauschen (dazu später mehr), hier ist EVENT_WRITE nur für Demonstrationszwecke vorhanden.
Als data-Attribut wird die Funktion process hinterlegt, diese soll genutzt werden wenn Schreib- oder Lesevorgänge bei Verbindungs-Sockets anfallen → beim listening-Socket haben wir accept angegeben, weil
hier andere Sachen gemacht werden müssen im Falle eines Lese-Events
15. Die Process-Funktion wird aufgerufen (ist in data für die Verbindungs-Sockets hinterlegt) wenn ein Ereignis auf einem Verbindungs-Socket auftritt → der Aufruf findet in der Schleife ganz am Ende des Programms statt
16. if mask & selectors.EVENT_WRITE wird ausgeführt wenn die Maske des Ereignisses ein Schreib-Ereignis enthält (es kann theoretisch mehrere Events gleichzeitig enthalten.
Da mask eine Bit-Mask ist und wie gesagt mehr als nur ein Schreib-Event gesetzt sein kann, legt man mask und selectors.EVENT_WRITE übereinander per &-Bit-Operator und erhält True wenn die Bits aus EVENT_WRITE gesetzt sind.
Im folgenden passiert nichts weiter in dem if-Statement, weil es in der Regel keinen Sinn hat auf dieses Ereignis zu lauschen (später mehr).
19. if mask & selectors.EVENT_READ wird ausgeführt wenn ein Read-Event vorliegt.
Es wird hier absichlich NICHT "else" benutzt, da die Maske ein Liste von Bits sind und ein Ereignis gleichzeitig Read-, als auch Write-Event sein kann für den gleichen Socket, es muss also auf beides geprüft werden (wenn man bei register() beides in der Maske angegeben hat und man sich für beides interessiert).
21. Der try-Block ist hier nicht notwendig, da bei vorliegen eines Read-Events Daten vorhanden sein müssen und die Exception nicht auftreten kann → habe ich einfach vergessen zu löschen
22. Ließt ganz normal die Daten aus dem Socket. Ggf. muss man hier eine Schleife einbauen, damit man den Socket komplett leer ließt (da man ja immer nur x Byte ließt)
28. Handhabt den Fall das "data" → die Daten die recv() zurückgegeben wurden leer waren → Socket wurde durch die Gegenstelle geschlossen.
Der Socket wird vom selector unregistered.
31. Der Socket muss nicht bzw. kann an dieser Stelle nicht geschlossen wurde. Da im Moment des Verbindungsabbaus durch die Gegenstelle der Socket bereits geschlossen wurde und im Betriebssystem nicht mehr existiert → der Aufruf von close() führt zu einer Exception.
Aufgeräumter Code
Der Code oben lauscht bei Connection-Sockets/Verbindungs-Sockets auf Read- und Write-Events.
Das lauschen auf Write-Events hat keinen praktischen Nutzen und wenn man obigen Code ausführt wird man sehen das Zeile 17 am laufenden Band Ausgaben macht (die Maske für Schreiben), weil das
Betriebssystem ständig Write-Events für den Socket meldet.
Das bedeutet auch das das Programm ständig in Aktion ist und die CPU auslastet, was dem Sinn der Nutzung von selector entgegensteht.
Das Lauschen auf Write-Events diente nur der Veranschaulichung, hier ist der "aufgeräumte" Code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
import socket
import selectors
HOST = "127.0.0.1"
PORT = 65445
selector = selectors.DefaultSelector()
def accept(sock, mask):
incomming_sock, addr = sock.accept()
print("Incomming connection", addr)
incomming_sock.setblocking(False)
selector.register(incomming_sock, selectors.EVENT_READ)
def process(sock:socket.socket, mask):
print(mask)
data = sock.recv(1024)
if data:
print("Data:", data)
sock.sendall(b"Zurueck" + data)
else:
print("Terminating connection")
selector.unregister(sock)
# No with-block here, as it will close the socket after leaving the
# block (which it will)
listening_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
listening_socket.bind((HOST, PORT))
listening_socket.listen(5)
listening_socket.setblocking(False)
# If something is being read at the socket -> its a incomming connection
# The socket is the one listening -> waiting for incomming connections, so not a connection A<->B
# The last parameter will be accessible in the key-object in the event as key.data -> you can put
# whatever you like in it (any object), most times you at least want the call back function here
selector.register(listening_socket, selectors.EVENT_READ, data=accept)
while True:
# Get the list of "event" happened since last time select() has been run for the registered sockets
events = selector.select()
# Unpack the list
for key, mask in events:
callback_function = key.data
socket = key.fileobj
callback_function(socket, mask)
Kurz zur Bit-Maske
Im Code taucht das hier auf und die Bemerkung das es sich um Bit-Masken handelt:
selector.register(incomming_sock, selectors.EVENT_READ | selectors.EVENT_WRITE, process)
if mask & selectors.EVENT_READ:Wenn man sich den Wert von EVENT_READ ansieht dann ist es Binär 1:
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
EVENT_WRITE ist Binär 2:
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
Der Bit-Oder-Operator ("|") setzt alle Bits auf 1, bei denen einer der Operanden an der Stelle 1 stehen hat - a oder b müssen 1 an der Stelle haben um 1 (True) zu setzen.
Bei selectors.EVENT_READ | selectors.EVENT_WRITE passiert also:
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
Und das Ergebnis ist:
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
Es sind also sowohl die Bits für Read, als auch die für Write aktiviert, als Dezimalzahl hat man 3.
Wenn man das dann auswertet benutzt man den "&"-Operator, der prüft ob in beiden Operatoren das Bit auf 1 steht - a UND b müssen an dieser Stelle 1 haben, damit es 1 (True) ergibt.
mask & selectors.EVENT_READ:Hat man eine Maske (Write und Read gesetzt):
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
und kombiniert mit selectors.EVENT_READ:
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
Ergibt das
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
Weil nur das 8. Bit in beiden Operanden auf 1 steht.
Da das Dezimal 1 ergibt und Dezimal 1 als True interpretiert wird, ergibt der Ausdruck True, damit würde die if-Anweisung
if mask & selectors.EVENT_READ:ausgeführt werden.
Das gleiche noch mal für selectors.EVENT_WRITE (der Inhalt von selector.EVENT_WRITE ist die 2. Zeile, 1. ist Read und Write gesetzt):
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
Ergibt:
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
aka. dezimal 2 und da 2 als True gewertet wird, wäre der entsprechende Ausdruck für Write ebenfalls True und eine if-Anweisung würde ggf. ausgeführt.
Man kann das ganze auch noch mal machen mit Write (2. Zeile) und einer Maske wo nur Read gesetzt ist (1. Zeile):
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
Das ergäbe:
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
Der Grund ist, ist das beim oberen Operand (der Maske) das 8. Bit 1 ist, beim unteren Operand (selectors.EVENT_READ) der 7., damit ergibt beim 7. Bit für beide Operanden & False → aka. 0 und beim 8. Operanden ebenfalls, da ja an diesen Stellen nicht beide Bits (&) 1 sind.
Das Ergebnis ist dezimal 0 aka. False und eine entsprechende if-Anweisung würde nicht ausgeführt werden.
Der Vorteil dieses Verfahrens ist, dass über die Bit-Maske mehrere Events/Zustände signalisiert werden können und man prüfen kann ob einer der gewünschten vorliegt.
